


Analizando logs a escala - TechDataTalk
Hoy vengo con un tema bastante interesante (o eso creo), y es el análisis de logs, el cual muchas veces lo hacemos innecesariamente o sin pensar en la escalabilidad

Muy buenas y bienvenido a la quinta edición de Tech Data Talk!
Hoy vengo con un tema bastante interesante (o eso creo), y es el análisis de logs, el cual muchas veces lo hacemos innecesariamente o sin pensar en la escalabilidad
De esto se habló en la Google Search Unconference, que se celebró el pasado viernes, una de las sesiones donde estuve era la de Lino, donde tocamos este tema

Para quién no lo sepa, los logs, explicado de una manera sencilla, son registros que el servidor guarda cada vez que pasa algo (una petición, alguien entra al server…)
Hay muchos tipos de logs, pero a nosotros normalmente nos van a interesar los logs de los web servers (apache, nginx…) ya que es donde se guardan los hits de los usuarios, bots….
En la mayoría de casos el análisis de logs, no es necesario, ya que no son webs muy grandes, pero en otras sí lo es, igualmente, a mi siempre me gusta analizarlos por si acaso
Otras veces, empresas muy grandes no dan acceso a sus logs por temas legales, y por lo tanto no podremos hacer nada, pongamos en el caso de que sí los tenemos
Para hacer análisis rápidos, hay herramientas muy buenas como:
Estas son herramientas muy orientadas a SEO, y que no necesitan de un conocimiento técnico muy avanzado, si tenéis estos conocimientos o un equipo que os lo pueda montar, podéis usar las siguientes soluciones:
CloudWatch, para centralizar el registros de logs, solo si usáis AWS
…..
Normalmente si trabajáis como SEOs in house, los equipos de IT suelen tener este tipo de herramientas de monitorización
Si queréis un punto intermedio, entre herramientas one shoot(es decir subes un archivo y ya, no es continuo) y otras herramientas más técnicas, podéis usar Python/JS/R… o herramientas No Code

Fuente: Stable Diffusion
Por ejemplo, si no tenéis mucho volumen de datos que analizar, con Make podéis conectaros a un server, o a S3 por ejemplo, traeros los logs y guardarlos en Big Query, o en Tinybird si queréis quitaros de problemas y tener una API Rest Real Time
Si ya tenéis volúmenes más grande de datos, podéis tirar por soluciones como Airbyte, donde puedes usar DBT para modificar y manipular datos
Por último, si ya tenéis muchos datos, yo lo que hago es montarme un pequeño proceso con Python y Apache Airflow o Kestra, para controlar los distintos trabajos, y ya después los guardáis en Clickhouse, Big Query, Tinybird…
Me podría tirar aquí un día hablando de esto, haré algún post cuando saque mi nueva web, donde lo explicaré todo mucho más a fondo, con ejemplos y demás
👨🎓 Paper Of The Week
ColossalAI - https://arxiv.org/abs/2110.14883
Hace poco hablé de Megatron ML, un paper que sacó Nvidia y que permitía entrenar modelos de Machine Learning mucho más rápido y de una manera mucho más efectiva
Pues, hoy os traigo ColossalAI, un sistema que permite entrenar Modelos de una manera muchísimo más rápido que Megatron, esto lo hace paralelizando el entrenamiento
En su Github, tenéis varios ejemplos con modelos como BERT, GPT-2, Stable Diffusion… donde podéis ver comparaciones tan bestia como esta
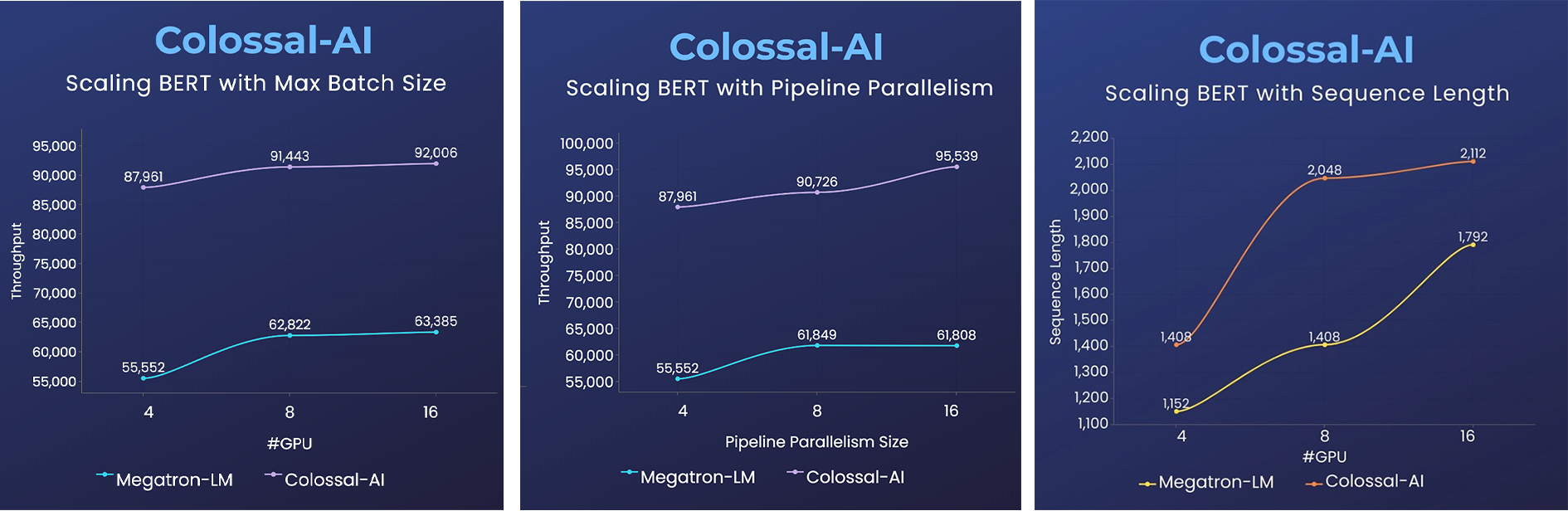
También podéis ver las 5 técnicas de paralelización que usan:
Data Parallelism
Pipeline Parallelism
Y por último, tiene implementación en Python y también tiene una imagen de Docker
🧪 This is F*cking Science
Dark enery en los agujeros negros - https://www.space.com/black-holes-create-dark-energy-first-evidence
En la universidad de Hawaii con la colaboración de otros 17 científicos han encontrado la primera evidencia de que los agujeros negros tienen “energía oscura” o dark energy en su core

Fuente: Stable Diffusion
Esto ya fue propuesto por Einstein en la teoría de la relatividad, pero hasta ahora no se había podido demostrar
Esto significa, que si es cierto todo esto, los agujeros negros muy antiguos podrían estar detrás de le expansión del universo e incluso de la creación del mismo
Y también supone que lo que se había descubierto hasta ahora sobre agujeros negros, no funciona, cuando hablamos de agujeros negros muy muy prematuros en el tiempo, es decir aquellos que se crearon en la creación del universo
📚 Biblioteca
Para terminar y como ya es costumbre vamos a terminar con unos cuantos artículos, podcasts…. que seguro te son muy útiles
Demostrate Search Predict, los estudiantes de Standford han sacado un framework para hacer Chatbots con GPT-3
Kestra, una herramienta de orquestación similar a Apache Airflow
Cómo hacer una auditoría ASO, charla en el Brighton SEO de Luis Bueno
Cómo tener impacto en SEO, un post muy bueno de Alberto Fernandez
SEO Testing, una herramienta TOP para hacer testing en SEO
Extraer datos de documentos templetizados, un post de hace unos años en Google AI
Hasta aquí la quinta edición de Tech Data Talk!
Espero que te haya gustado, no olvides dejar un comentario y compartirlo 😏