


Machine Learning Ops, de la teoría a la práctica - TechDataTalk #011

Muy buenas y bienvenido a la onceava edición de Tech Data Talk!
Espero que hayáis pasado una buena semana santa, hoy vengo con un tema que considero bastante importante y del que nunca se habla, ya que como todos sabemos es mucho más fácil hablar de lo simple
La carga cognitiva que significa hablar de algo complejo es mucho mayor que hablar de algo simple y que “entra fácil”, como dice Recuenco, haber elegido Telecinco
Total, que me voy por las ramas, hoy vamos a hablar de como poner modelos de Machine Learning en producción y como hacer procesos de aprendizaje continuo ayudándonos de herramientas de CI/CD
Pd: Voy a hacer una serie de varias ediciones hablando de esto
Uno de los grandes problemas de los modelos de Machine Learning a parte de entrenarlos, para lo cual necesitas muchos datos y sobre todo dinero para pagar GPUs, el problema es usarlos en producción

En la gran mayoría de las herramientas y webs, no te puedes permitir tener tiempos de respuesta muy altos, por ejemplo a la hora de hacer algo tan simple como clustering, ya no me meto en modelos de decisión como tiene Netflix, Airbnb…
Para todo esto existe una disciplina llamada Machine Learning Ops, donde se dedican única y exclusivamente a seguir el siguiente proceso (sobre todo la tercera parte):

Estas tres fases las podríamos dividir para explicarlo de una manera mucho más sencilla en los siguientes puntos:
Pipelines de datos (ingeniería de datos)
Pipelines de Machine Learning (aprendizaje, monitorización…)
Estrategias de deployment
En esto entraré en próximas ediciones, ya que voy a hacer un serie sobre todo este tema ya que es muy amplio, y a mi personalmente me parece muy interesante
Pero al final lo que buscamos con todo esto es automatizar procesos tanto de integración, deployment, entrenamiento, monitoreo…
Todo esto con el fin de ir iterando e ir creando mejores y mejores modelos con el tiempo con más y más datos (aunque esto no siempre es así)
También hay otros puntos que trataré como por ejemplo, versiones de modelos de ML, monitoreo, que infraestructuras usar…
Pero esto será en próximas ediciones, hoy simplemente ha sido una pequeña introducción a un mundo apasionante
👨🎓 Paper Of The Week
Infraestructura para manejo de datos en tiempo real en Uber => https://arxiv.org/pdf/2104.00087.pdf
Aunque no es un paper de IA y tampoco es muy nuevo, igualmente me parece un paper muy interesante de leer, escalar infraestructuras es de las cosas más complejas que hay
Como podemos leer hay principalmente 3 problemas a los que se enfrentan:
Escalar datos
Escalar usuarios
Escalar los casos de uso
Como podemos ver en el paper, la infra de uber está compuesta por un sistema de mensajes (RabbitMQ, Kafka..), workers que consumen y manejan estos mensaje y BBDDs del tipo OLAP (Apache pinot por ejemplo)
Al final acaban usando Kafka como broker de mensajes (se suele usar más que Rabbit), Apache Flink para el procesado de datos y Apache Pinot como OLAP
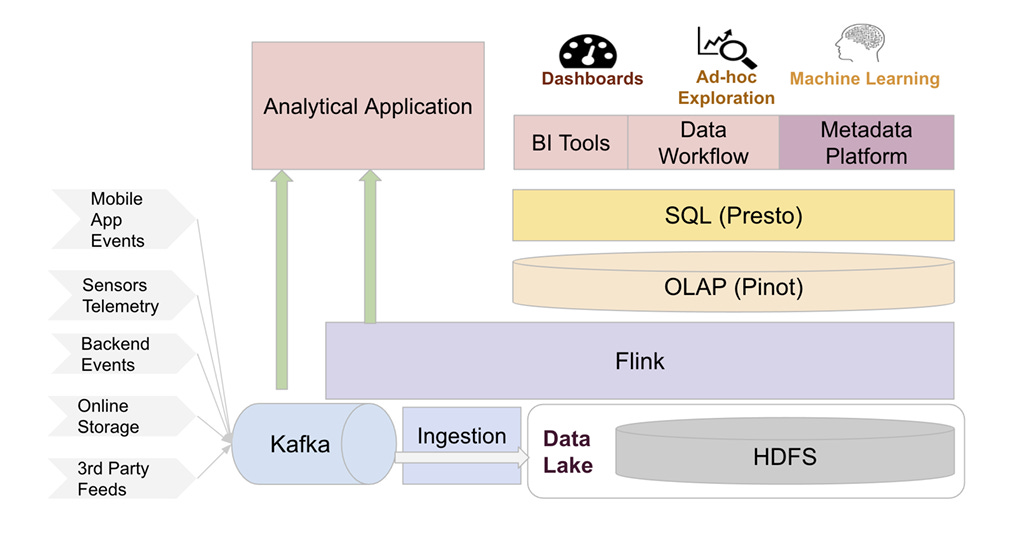
Al final lo que buscan con todo esto es una infra robusta y que sea capaz de aguntar los millones de mensajes que reciben cada día
🧪 This is F*cking Science
Tres monas están embarazadas de pseudo-embriones => https://www.nature.com/articles/d41586-02
Esto es uno de los pasos más importante en cuanto a edición genética se refiere y a lo que en un futuro posiblemente sea un método de tener hijos
En otras newsletter ya hemos hablado de este tema y de lo que puede suponer la edición genética y la creación de pseudo-humanos
Igualmente que seamos capaces de recrear el proceso de embarazo y ver como sucede todo el proceso de gestación y sacar conclusiones de ahí es una pasada
A partir de aquí seguro sacan muchas conclusiones de los primeros días de un embrión, seguramente podemos curar otras tantas enfermedades
Aquí también hay una parte de Ética muy importante, y sobre el que algún día discutiremos
📚 Biblioteca
Para terminar como siempre voy a dejar algunos posts, podcast… que son bastante interesantes la verdad:
La importancia de hacer buena ingeniería, post muy TOP de Javi Santana
Input metrics para SEO, una newsletter muy chula de Seo MBA
Hasta aquí la newsletter de hoy, espero que te haya gustado y si has llegado hasta aquí, podrías dejarme un comentario o un mensaje dando tu opinión y que te gustaría ver en las próximas ediciones