


Separando el big data del humo - TechDataTalk #7
Hoy vengo con un tema un poco polémico cuanto menos, como ya habrás visto, hoy vamos a separar el Big Data del humo

Muy buenas y bienvenido a la séptima edición de Tech Data Talk!
Hoy vengo con un tema un poco polémico cuanto menos, como ya habrás visto, hoy vamos a separar el Big Data del humo
Muuucha gente se llena la boca hablando de Big Data y de la cantidad de datos que mueven, pero hay muy pocos que de verdad hagan esto
Hacer Big Data de verdad es muy caro y está al alcance de muy poca gente, por un simple hecho, hay muy poca gente con la capacidad de generar semejante cantidad de datos
Pero antes de nada, vamos a ver las principales características que tiene el big data:
Volumen
Velocidad
Variedad
Veracidad
Valor
Variabilidad
Las 6 V’s del Big data => https://www.geeksforgeeks.org/5-vs-of-big-data/
Es decir, frente a otros tipos de datos, con Big Data, vamos a manejar datasets que contienen muchos datos distintos(fotos, vídeos, textos…)
Y además la calidad del dato no siempre está garantizada, ya que no siempre podemos asegurarnos de que todos los datos que tenemos, se obtienen de una manera adecuada y sin problemas
Además, cuando vamos a hacer big data, normalmente, usamos herramientas diferentes a cuando analizamos una menor cantidad de datos, por ejemplo:
Clickhouse
AWS Kinesis
Apache Beam
Apache Hadoop
Apache Airflow
AWS Redshift
AWS Lake Formation
…….
Normalmente, solemos optar por soluciones cloud ya que son mucho mas simples de usar y de escalar, que soluciones más tradicionales

Prompt: create a photo of big data being proccesed in AWS, big data, cloud computing, AWS --v 4
Llevándolo a “nuestro mundo” es decir al SEO, Marketing… quitando casos excepcionales de webs muy grandes tipo Mil anuncios, Coches.net… nadie tiene la capacidad de montar todo este tinglado
No solo por los costes que conlleva, si no también por el conocimiento y el equipo que se necesita para programar, mantener, actualizar… todo esto y que impacte a negocio
Nunca se nos puede olvidar que si hacemos algo de este tipo, tiene que tener un impacto en negocio importante ya que si no, nada de esto tiene sentido
En próximas ediciones hablaré de herramientas, procesos… para hacer Big Data, que aunque no lo podamos hacer, siempre se puede frikear un poco, dejo por aquí una charla de lino muy interesante sobre el tema
https://es.slideshare.net/errioxa/seo-logs-y-big-data-lino-uruuela-en-seonthebeach-2016
👨🎓 Paper Of The Week
Understanding Self-Attention => https://sebastianraschka.com/blog/2023/self-attention-from-scratch.html
Uno de los puntos que hace que los Transformers sean tan “especiales” o mejor dicho, que sean el modelo por excelencia y que todo el mundo usa, es lo que se llama atención
De una manera muy simple, la “atención” le permite al modelo entender el contexto alrededor de una palabra, a través de procesar conjuntos de palabras o frases, en vez de ir palabra por palabra
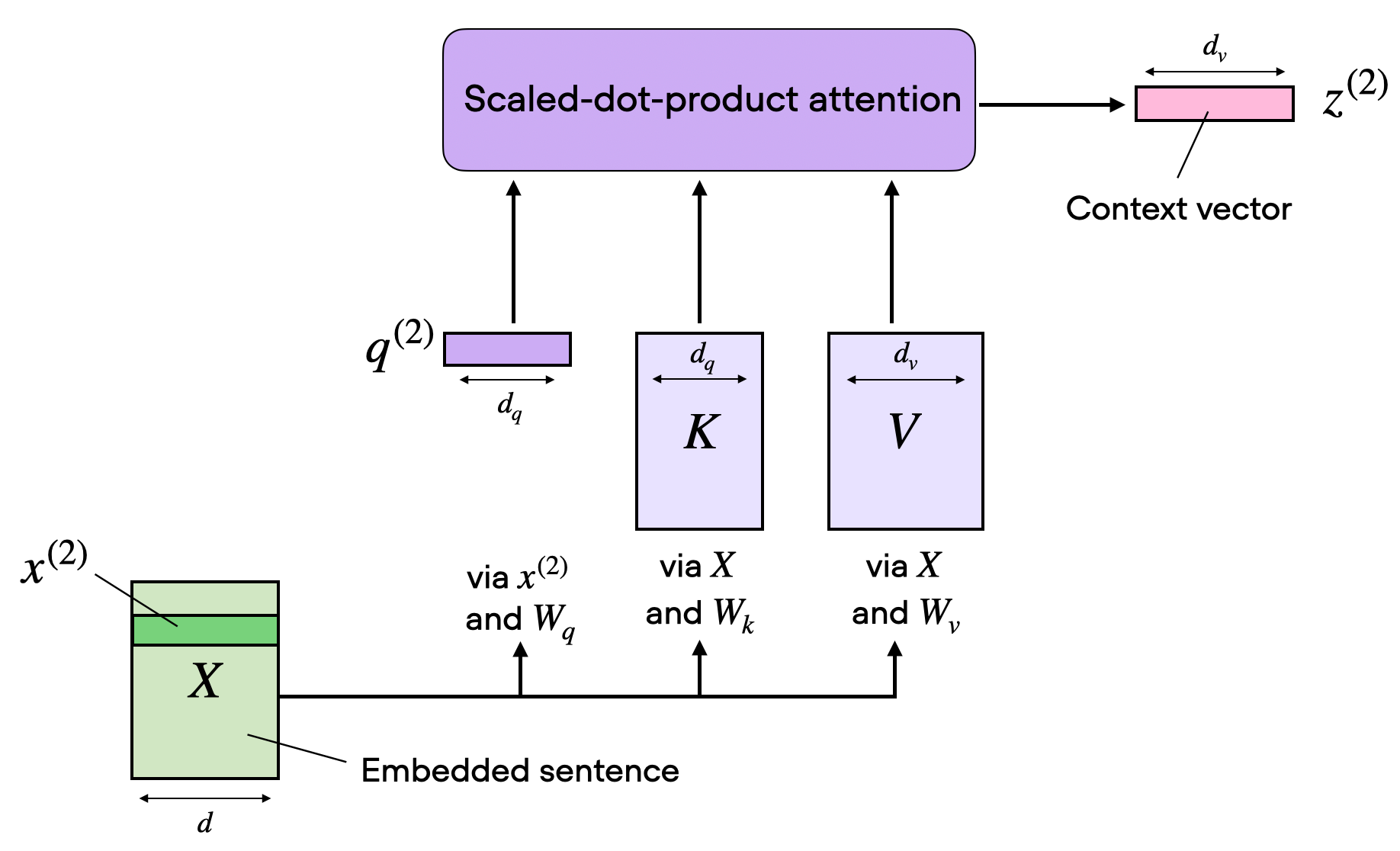
Este es un gráfico sacado del post anterior, donde podemos ver como funciona lo que se llama “self-attention”, pero los modelos transformers usan lo que se llama “multi head-attention”
Que sería algo más así
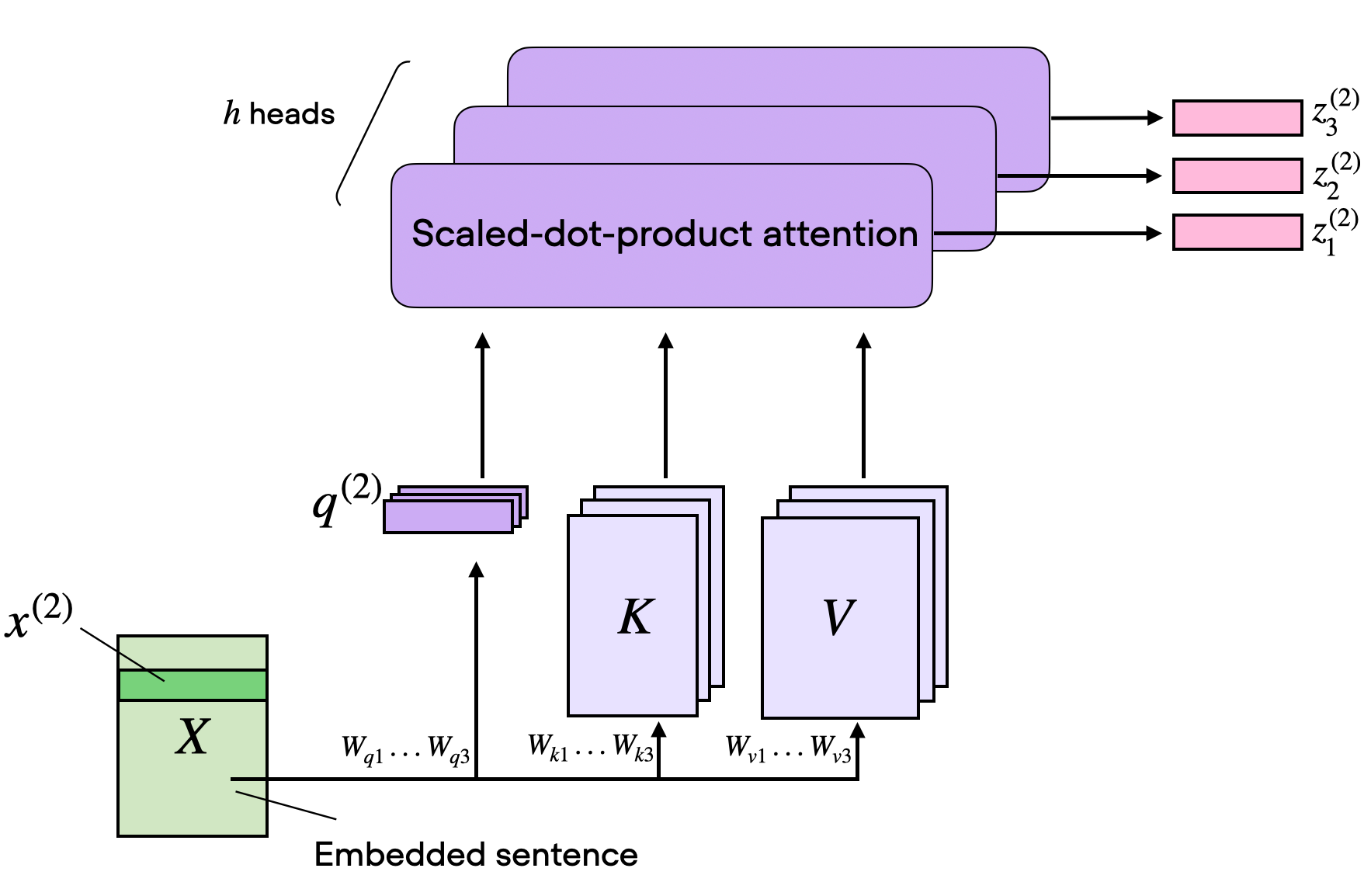
Si queréis entender todo esto, os recomiendo leer el post, porque además de explicarlo lo programa en Python
🧪 This is F*cking Science
International Summit on Genome Editing => https://www.nature.com/articles/d41586-023-00625-w
Esta semana se celebra en Londres el mayor congreso sobre edición genética, un tema muyy interesante y que tiene un arma de doble filo
Por que digo esto, la edición genética nos puede ayudar a “cortar de raíz” enfermedades como el VIH pero también puede crear distintas razas de humanos

Prompt: simulate genome editing, CRISPR, biologoy, dna, colorful --v
Al final, si somos capaces de modificar el ADN se podrán crear humanos más rápidos, otros más inteligentes, otros más alto…
Y si, esto da bastante miedo ya que habría distintas clases de humanos o incluso super-humanos, pero, si somos capaces de controlar y regularlo puede hacernos avanzar una barbaridad

📚 Biblioteca
Para terminar como siempre voy a dejar algunos posts, podcast… que son bastante interesantes la verdad:
Shorts sobre SEO y estrategia, muy recomendado el canal de Arturo Marimón
ChatGPT + Google Sheets, vídeo TOP de Phoenix, cracks donde los haya
Heurísticos de Neilsen, un básico de UX
El equilibrio de los extremos, un post muy bueno de Corti y con el que me siento muy identificado
ChatGpt Prompts, una presentación muy chula de Txetxu
Guía sobre interlinking, una guia muy buena del equipo de Laika
Hasta aquí la newsletter de hoy, espero que te haya gustado y si has llegado hasta aquí, podrías dejarme un comentario o un mensaje dando tu opinión y que te gustaría ver en las próximas ediciones